class: center, middle, inverse, title-slide .title[ # Metody przetwarzania<br>i analizy danych ] .subtitle[ ## Grupowanie ] .author[ ### © Łukasz Wawrowski ] --- # Podział metod Uczenie nadzorowane - końcowy wynik jest znany - klasyfikacja - regresja Uczenie nienadzorowane - końcowy wynik nie jest znany - grupowanie obiektów - grupowanie cech --- # Podział metod 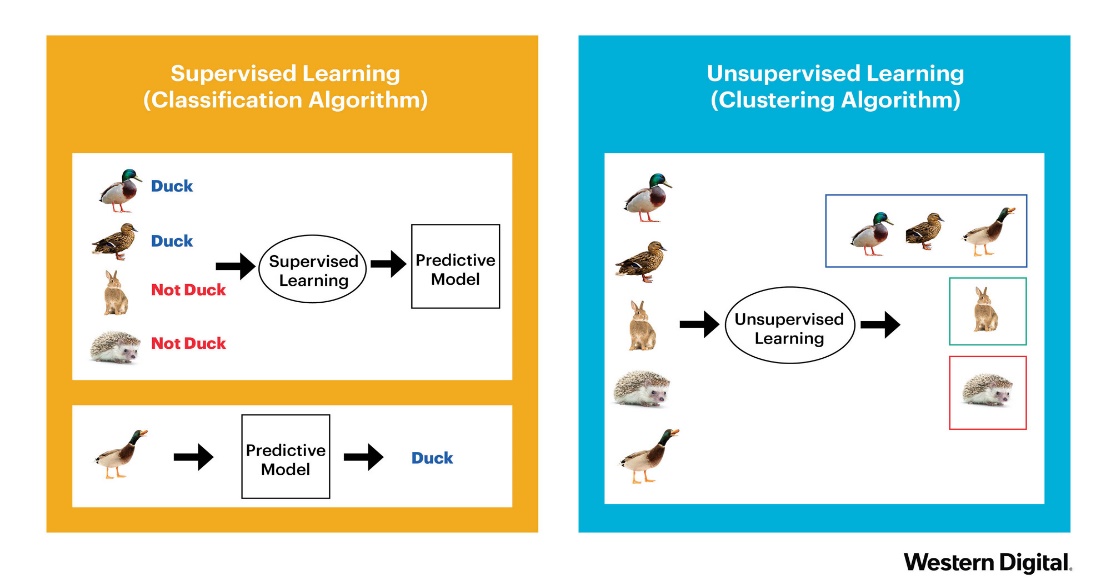 --- # Idea Liczenie odległości pomiędzy analizowanymi obiektami. Cechy opisujące obiekty mogą być wyrażone w różnych jednostkach np. w segmentacji klientów: - wiek w latach - wydatki na zakupy - liczba wizyt w sklepie W związku z tym konieczna jest **normalizacja** cech czyli pozbawienie ich mian. Najpopularniejszą metodą normalizacji jest standaryzacja: `\(z=\frac{x-\bar{x}}{s}\)` gdzie: `\(\bar{x}\)` - średnia, `\(s\)` - odchylenie standardowe. --- # Standaryzacja <!-- --> --- # Metoda k-średnich 1. Wskaż liczbę grup `\(k\)`. 2. Wybierz dowolne `\(k\)` punktów jako centra grup. 3. Przypisz każdą z obserwacji do najbliższego centroidu. 4. Oblicz nowe centrum grupy. 5. Przypisz każdą z obserwacji do nowych centroidów. Jeśli któraś obserwacja zmieniła grupę - przejdź do kroków nr 3 i 4, a w przeciwnym przypadku zakończ algorytm. --- # Metoda k-średnich  [źródło](https://dashee87.github.io/data%20science/general/Clustering-with-Scikit-with-GIFs/) --- # Przykład Segmentacja [klientów sklepu](http://www.wawrowski.edu.pl/data/klienci.csv) w oparciu o następujące dane: - klientID - identyfikator klienta - plec - płeć - wiek - wiek - roczny_dochod - roczny dochód wyrażony w tys. dolarów - wskaznik_wydatkow - klasyfikacja sklepu od 1 do 100 --- # Implementacja Metoda iteracyjna - k-średnich: ```python from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=5, init="k-means++") clusters_kmeans = kmeans.fit_predict(z) ``` --- # Wybór liczby grup **Metoda łokcia (wykres osypiska)** Szukamy tzw. „łokcia” na wykresie inercji, czyli miejsca, gdzie dalsze zwiększanie liczby klastrów nie powoduje już dużego spadku błędu. **Indeks Calińskiego-Harabasza** Im większa wartość tego indeksu, tym lepsze (bardziej zwarte i rozdzielne) klastry. Najwyższy pik sugeruje najlepszą liczbę klastrów. --- class: inverse # Zadanie Dokonaj grupowania danych dotyczących [32 samochodów](http://www.wawrowski.edu.pl/data/auta.csv) według następujących zmiennych: pojemność, przebieg, lata oraz cena. <countdown-timer class="countdown" id="timer_b4c8cfb2" minutes="10" seconds="0" update-every="1" tabindex="0" style="top:0;right:0;"></countdown-timer> --- # Metoda hierarchiczna 1. Każda obserwacji stanowi jedną z `\(N\)` pojedynczych grup. 2. Na podstawie macierzy odległości połącz dwie najbliżej leżące obserwacje w jedną grupę. 3. Połącz dwa najbliżej siebie leżące grupy w jedną. 4. Powtórz kroki nr 2 i 3, aż do uzyskania jednej grupy. --- # Metody tworzenia wiązań | Metoda | Miara odległości | Zalety | Wady | | -------- | ----------------- | ----------------------------------- | ---------------------------------- | | Single | Najbliższe punkty | Działa dla nieregularnych kształtów | Efekt łańcucha, wrażliwość na szum | | Complete | Najdalsze punkty | Zwarte klastry | Może zniekształcać duże klastry | | Average | Średnia odległość | Dobry kompromis | Koszt obliczeniowy | | Ward | Wzrost wariancji | Zwarte, równoliczne klastry | Źle radzi sobie z nieregularnymi | --- # Implementacja Metoda hierarchiczna: ```python from sklearn.cluster import AgglomerativeClustering hier = AgglomerativeClustering(n_clusters=5, linkage="ward") clusters_hier = hier.fit_predict(z) ``` --- # Dendrogram <img src="img/dendrogram.png" height="500px"> [źródło](https://www.data-to-viz.com/graph/dendrogram.html) --- class: inverse # Zadanie Do danych z poprzedniego zadania zastosuj metodę hierarchiczną. <countdown-timer class="countdown" id="timer_f37a6a5b" minutes="10" seconds="0" update-every="1" tabindex="0" style="top:0;right:0;"></countdown-timer> --- # Inne algorytmy grupowania Algorytmów grupowania jest bardzo wiele. - [DBSCAN](https://pl.wikipedia.org/wiki/DBSCAN) - [K-modes](https://www.geeksforgeeks.org/machine-learning/k-mode-clustering-in-python/) - dla danych kategorycznych - [Grupowanie rozmyte](https://www.geeksforgeeks.org/machine-learning/ml-fuzzy-clustering/) - obiekt może przynależeć do kilku grup Niektóre z nich mają na celu wykrywanie anomalii, dzieląc dane zawsze na dwie grupy - obserwacji nietypowych oraz typowych. - [Local Outlier Factor](https://en.wikipedia.org/wiki/Local_outlier_factor) - [One Class SVM](https://scikit-learn.org/stable/modules/generated/sklearn.svm.OneClassSVM.html) --- # Skuteczność algorytmów <img src="img/cluster_comparison.png" width="600px"> Źródło: https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_comparison.html --- # Redukcja wymiarowości W rzeczywistych zbiorach danych obiekty często opisane są przez dużą liczbę cech. Duża liczba zmiennych może powodować: - trudności w wizualizacji danych, - wydłużenie czasu obliczeń, - występowanie silnie skorelowanych cech, - pogorszenie skuteczności algorytmów. Redukcja wymiarowości polega na zastąpieniu wielu cech mniejszą liczbą nowych zmiennych zachowujących najważniejsze informacje o danych. --- # Analiza głównych składowych (PCA) PCA (*Principal Component Analysis*) tworzy nowe zmienne zwane **głównymi składowymi**. Każda składowa jest kombinacją liniową oryginalnych cech. Tak stworzone zmienne: - są wzajemnie nieskorelowane, - wyjaśniają możliwie dużą część wariancji danych. Pierwsza składowa wyjaśnia największą część zmienności, druga największą z pozostałej itd. --- # Implementacja PCA ```python from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA scaler = StandardScaler() z = scaler.fit_transform(x) pca = PCA(n_components=2) x_pca = pca.fit_transform(z) ``` Parametr `n_components` określa liczbę nowych wymiarów. --- # PCA - ocena jakości ```python print(pca.explained_variance_ratio_) ``` Przykładowy wynik: ```python [0.62, 0.24] ``` Oznacza to, że: - pierwsza składowa wyjaśnia 62% wariancji, - druga składowa wyjaśnia 24% wariancji. Łącznie zachowano 86% informacji zawartej w danych. Po redukcji do dwóch wymiarów można łatwo zwizualizować wyniki grupowania, ale wartości na osiach nie mają żadnej interpretacji. --- # t-SNE t-SNE (*t-Distributed Stochastic Neighbor Embedding*) jest nieliniową metodą redukcji wymiarowości. Jej celem jest zachowanie lokalnych sąsiedztw pomiędzy obserwacjami. Podobne obiekty pozostają blisko siebie również po redukcji wymiarów. --- # Implementacja t-SNE ```python from sklearn.manifold import TSNE tsne = TSNE( n_components=2, random_state=42 ) x_tsne = tsne.fit_transform(z) ``` --- # UMAP UMAP (*Uniform Manifold Approximation and Projection*) jest nowoczesną metodą redukcji wymiarowości. Łączy zalety PCA i t-SNE: - zachowuje lokalną strukturę danych, - lepiej odwzorowuje strukturę globalną, - działa szybciej dla dużych zbiorów danych. Coraz częściej stosowany jest jako standardowa metoda wizualizacji danych wielowymiarowych. --- # Implementacja UMAP ```python from umap import UMAP umap = UMAP( n_components=2, random_state=42 ) x_umap = umap.fit_transform(z) ``` --- class: inverse # Zadanie Dla danych dotyczących samochodów wykonaj standaryzację cech, zredukuj dane do dwóch wymiarów i porównaj wyniki PCA oraz UMAP. <countdown-timer class="countdown" id="timer_84401653" minutes="10" seconds="0" update-every="1" tabindex="0" style="top:0;right:0;"></countdown-timer> --- # Paradoks Simpsona Efekt działania kilku grup wydaje się odwrócony, kiedy grupy są połączone. <img src="img/simpson.png" width="600px"> -- - Nabór na Uniwersytecie w Berekley w 1951 roku: spośród kandydatów przyjęto 45% mężczyzn i 30% kobiet. - Uniwersytet został oskarżony o seksizm i sprawa została skierowana do sądu. --- # Zbiór palmerpenguins [Zbiór danych na temat pingwinów](https://github.com/allisonhorst/palmerpenguins) <img src="img/lter_penguins.png" width="600px"> --- class: inverse, center, middle # Pytania?