2 Wizualizacja danych
Bardzo istotną częścią statystyki jest wizualizacja wyników. Poprawne korzystanie z wykresów wymaga poznania kilku, czasami nieoczywistych, zasad:
- efekt 3D na wykresach zaburza percepcje i utrudnia porównywanie danych,
- wykresy liniowe służą przede wszystkim do prezentacji zmian w czasie,
- …
Zasoby internetowe są pełne przykładów i wzorców tworzenia wykresów:
- Graficzna prezentacja danych statystycznych - Wykresy, mapy, GIS
- Zbiór esejów o wizualizacji danych
- Flowing Data
- D3
W analizie statystycznej bardzo ważne jest pojęcie rozkładu cechy.
Rozkładem empirycznym cechy nazywamy przyporządkowanie kolejnym wartościom zmiennej (\(x_{i}\)) odpowiadającym im liczebności (\(n_{i}\)). Rozkład odzwierciedla strukturę badanej zbiorowości z punktu widzenia określonej cechy.
Najdogodniejszym sposobem graficznej prezentacji rozkładu jest histogram przedstawiający częstość poszczególnych kategorii. Histogram można utworzyć na podstawie tabeli przestawnej. W sytuacji kiedy nie wszystkie wartości są reprezentowane histogram może wyglądać dziwnie, dlatego stosuje się grupowanie wartości. W Excelu jest to możliwe z wykorzystaniem funkcji CZĘSTOŚĆ. Funkcja ta oblicza rozkład częstości występowania wartości w zakresie wartości (działa po zaznaczeniu odpowiedniego zakresu z~kombinacją CTRL+SHIFT+ENTER). Prawe przedziały są domknięte.
2.1 Rodzaje rozkładów
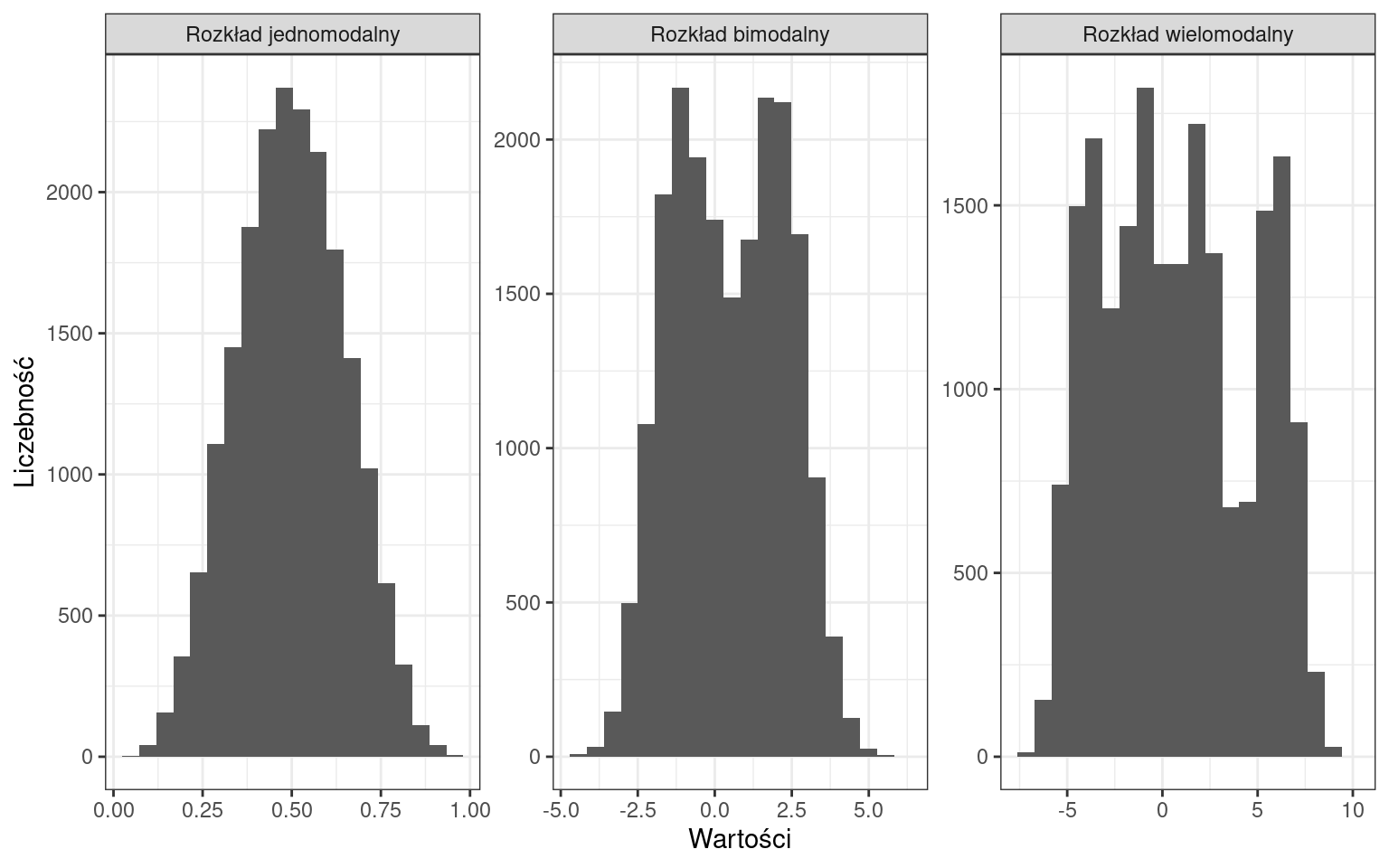
Ze względu na liczbę punktów ekstremalnych:
Ze względu na rodzaj zmienności:
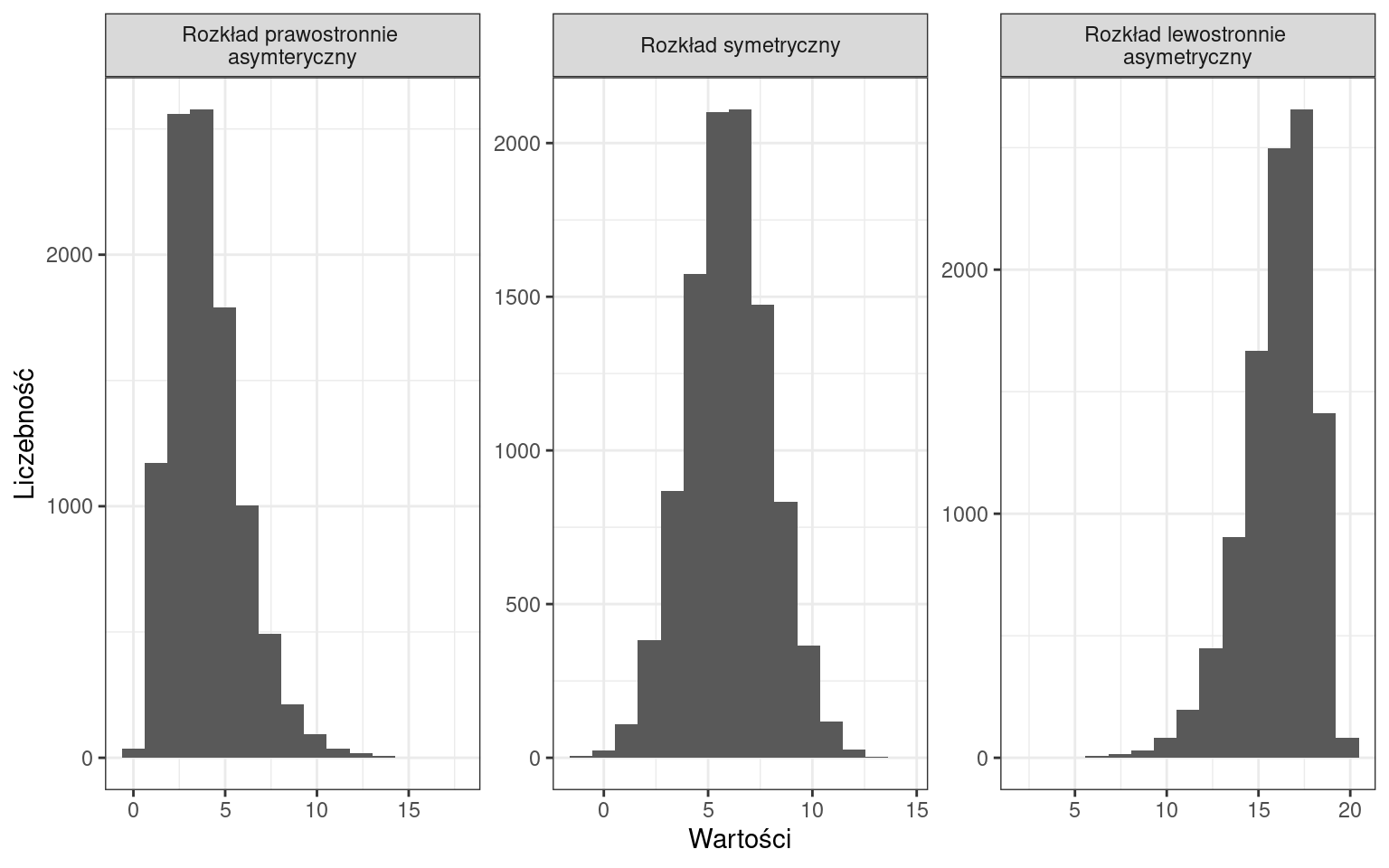
Ze względu na skupienie wokół średniej:
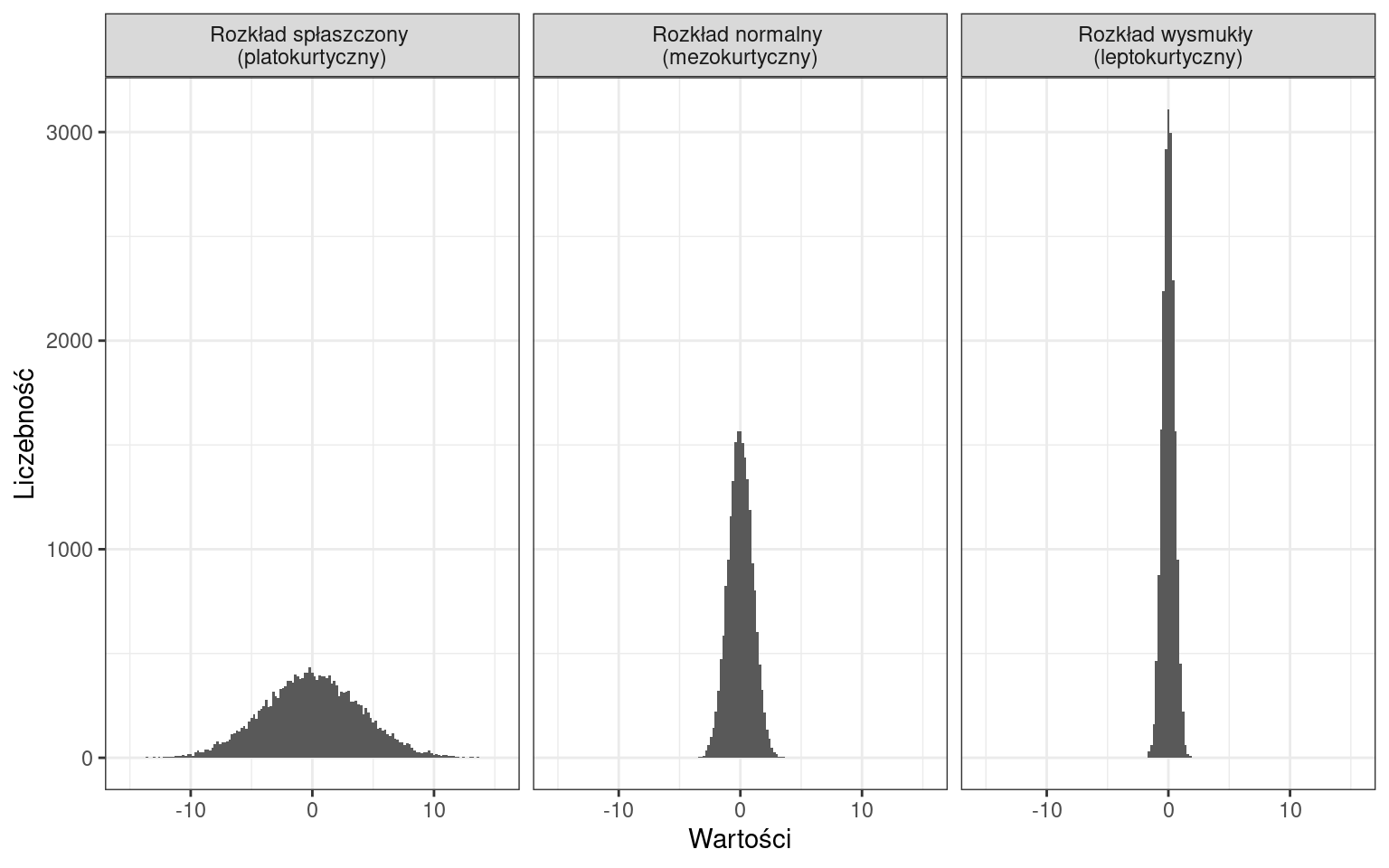
W ten sposób możemy opisywać histogramy, natomiast w dalszej części zajęć dowiemy się jakie miary definiują te cechy.
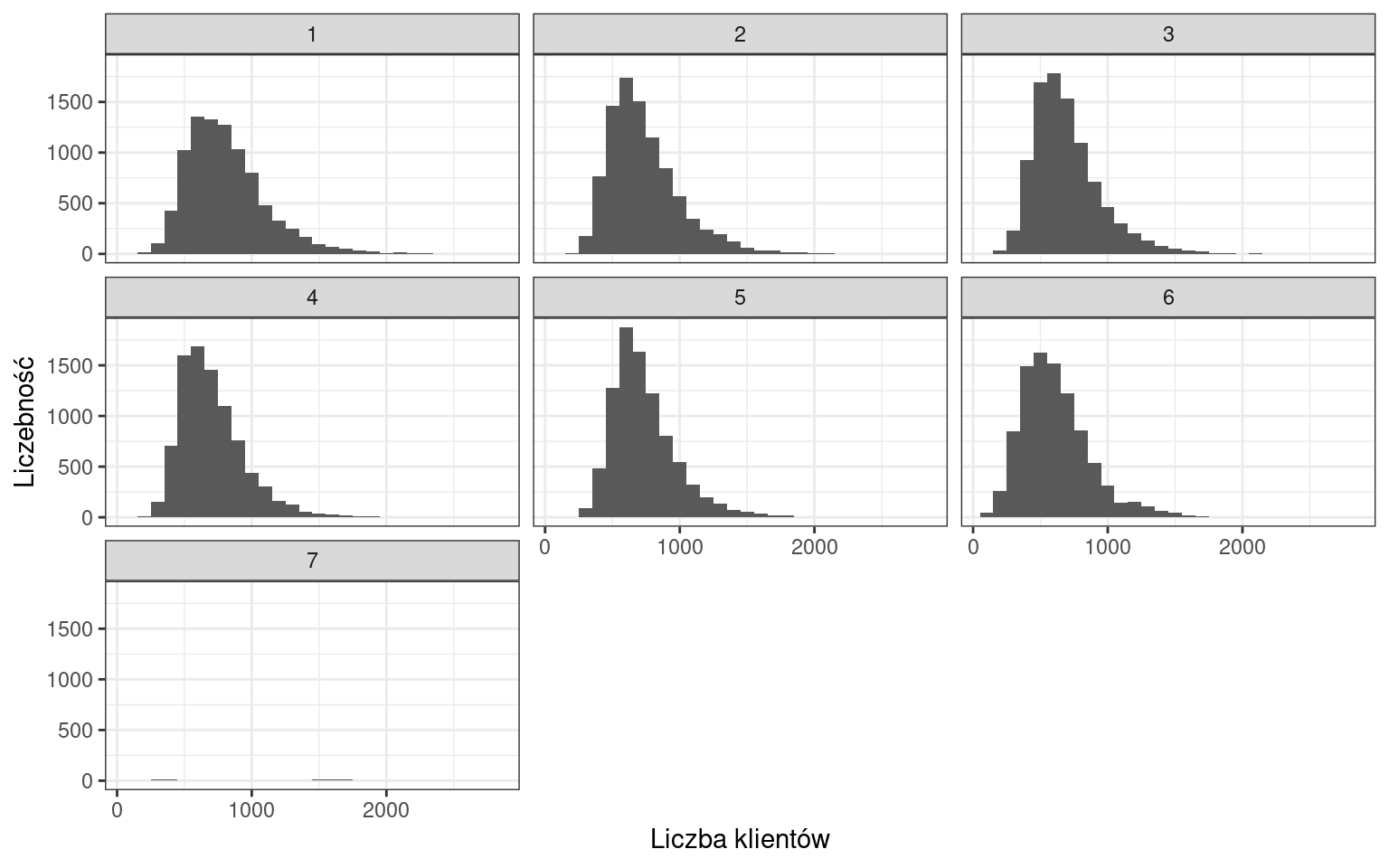
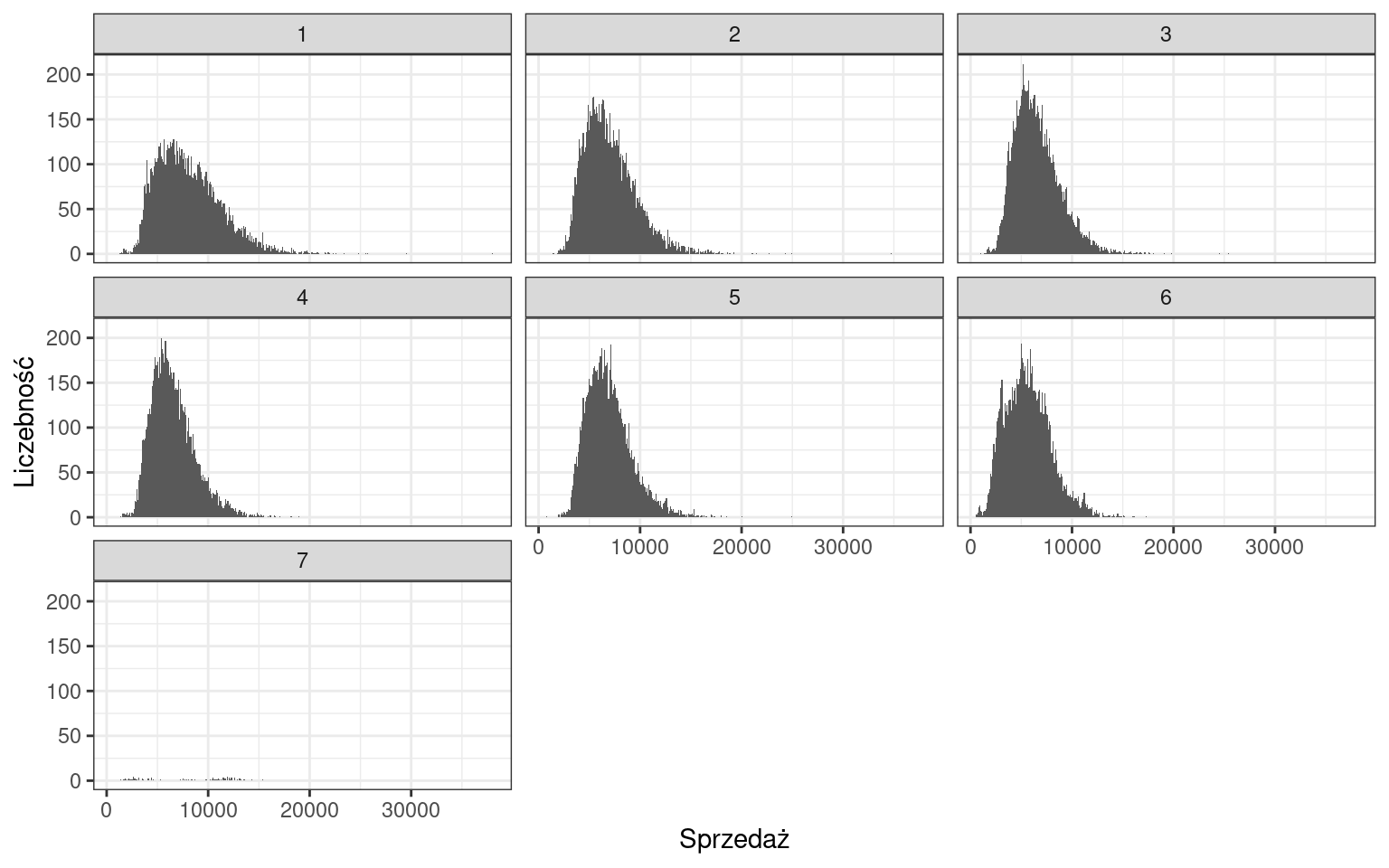
Przejdźmy do naszego zbioru danych i przeanalizujmy liczbę klientów.
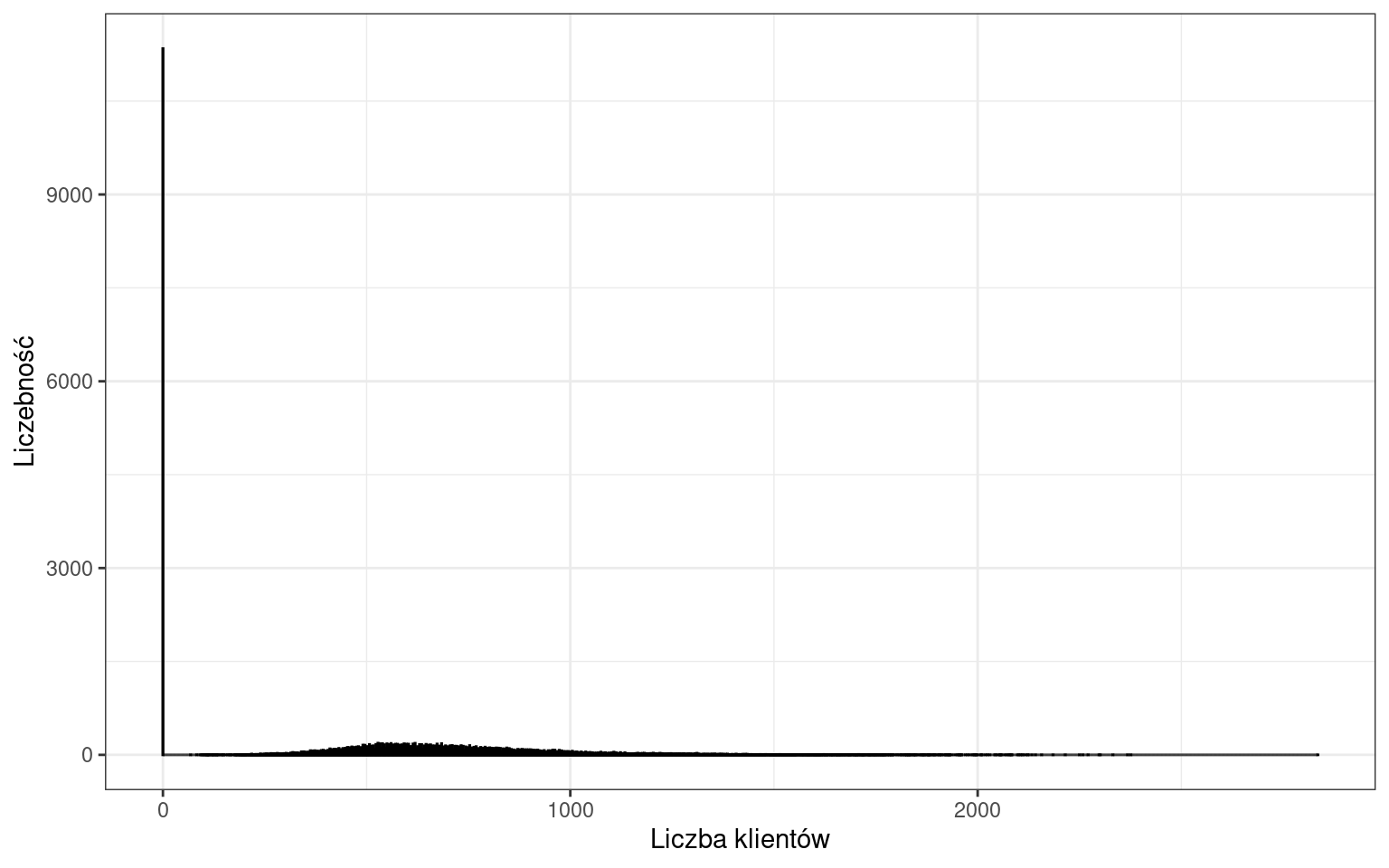
Okazuje się, że występuje bardzo dużo wartości równych 0, wynikających z obserwacji dni, w których sklep był zamknięty. Musimy wyeliminować zera z naszych danych.
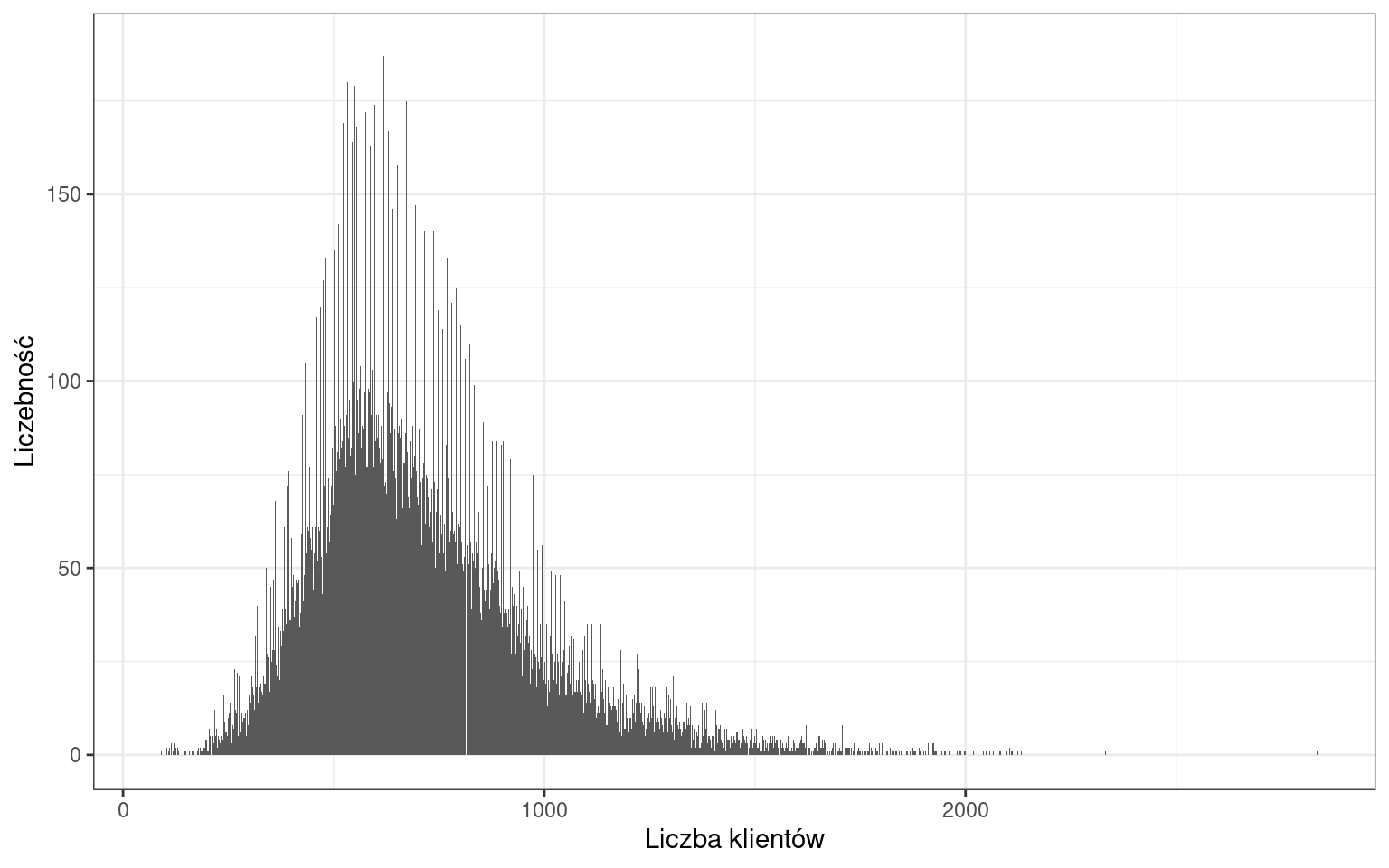
Obecnie rozkład liczby klientów jest dużo bardziej czytelny. Niemniej możemy zauważyć wiele wartości, które występują częściej od pozostałych. Zgrupujmy słupki w przedziałach o rozpiętości 100 klientów.
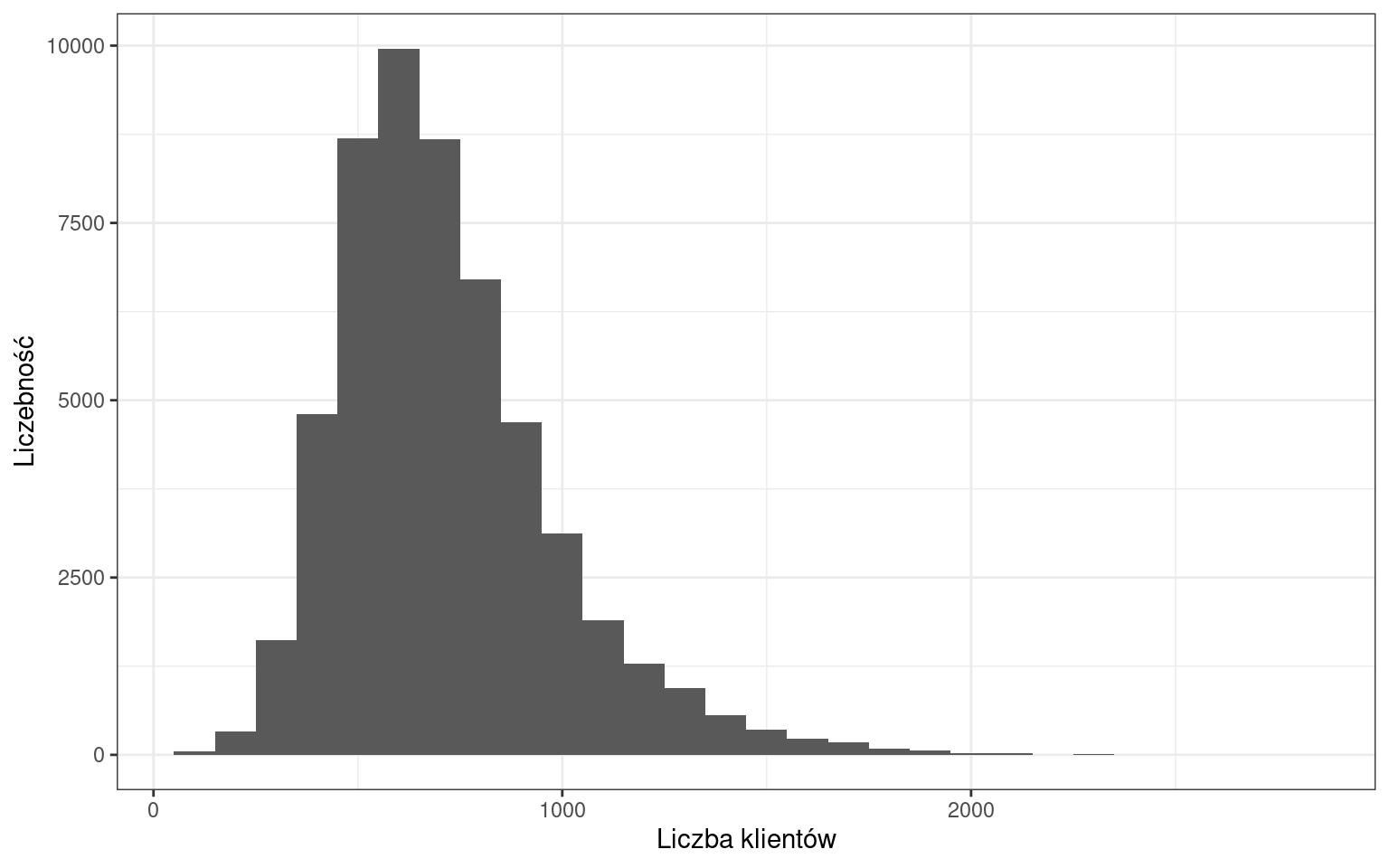
Najliczniejszą kategorią stanowią dni, w których liczba klientów pochodziła z przedziału 500-600 osób. Można także zaobserwować, że rozkład charakteryzuje się asymetrią prawostronną.
2.2 Szeregi statystyczne
Przeprowadzając powyższe grupowanie utworzyliśmy kilka rodzajów szeregów statystycznych.
Szereg statystyczny jest to ciąg wielkości statystycznych usystematyzowanych według określonego ściśle kryterium. Powstaje on w wyniku grupowania bądź porządkowania. Stanowi podstawę dla prowadzenia numerycznej analizy statystycznej.
- szereg prosty to wykaz wszystkich wariantów badanej cechy np. liczba klientów dla każdego sklepu danego dnia
- szereg rozdzielczy jednostkowy (punktowy) wykaz wariantów cechy i liczebności poszczególnego wariantu np. szereg utworzony z wykorzystaniem tabeli przestawnej
- szereg rozdzielczy przedziałowy zamknięty o równych przedziałach klasowych wykaz zgrupowanych wariantów cechy i liczebności poszczególnych wariantów np. szereg utworzony z wykorzystaniem funkcji CZĘSTOŚĆ
- szereg rozdzielczy przedziałowy zamknięty o nierównych przedziałach klasowych
- szereg rozdzielczy przedziałowy otwarty - kiedy w pierwszej lub/i ostatniej grupie znajduje się przedział otwarty (zwrot poniżej/powyżej)
2.3 Dystrybuanta
Kolejnym zagadnieniem związanym z rozkładem cechy jest dystrybuanta.
Dystrybuanta empiryczna to funkcja ukazująca skumulowany rozkład cechy w n-elementowej zbiorowości. Funkcję \(F(x)\) definiuje się jako skumulowane prawdopodobieństwo wystąpienia - tj. sumę prawdopodobieństw od danego przedziału klasowego w rozkładzie empirycznym badanej cechy. Wyraża się wzorem:
\[F(x)=\sum\limits_{x_{i}<x}{p_{i}},\]
gdzie: \(p_{i}\) — prawdopodobieństwo wystąpienia wariantu.
Dystrybuanta empiryczna jest funkcją:
- niemalejącą,
- lewostronnie ciągłą.
Dystybuanta ciągła liczby klientów
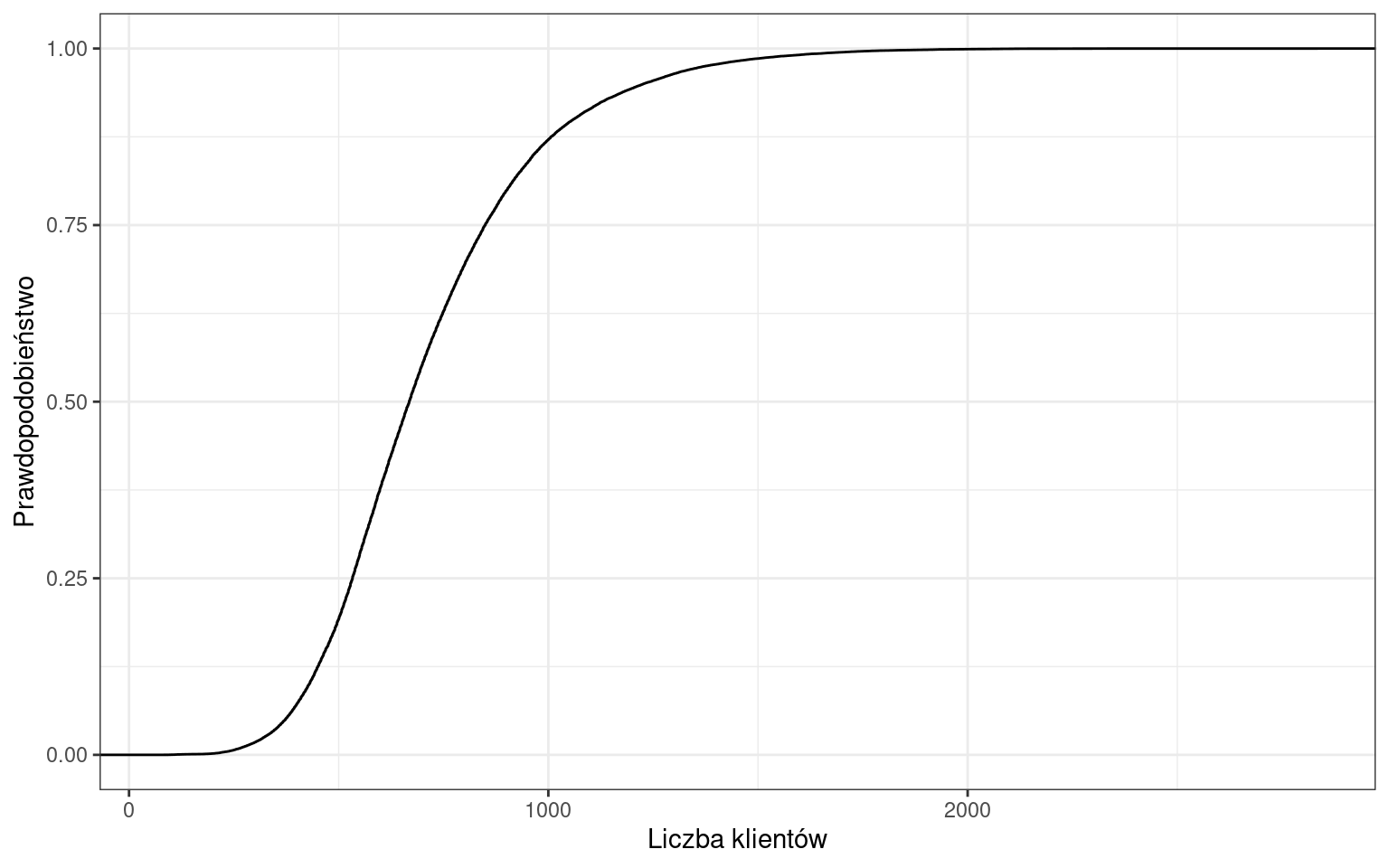
Dystrybuanta skokowa liczby klientów
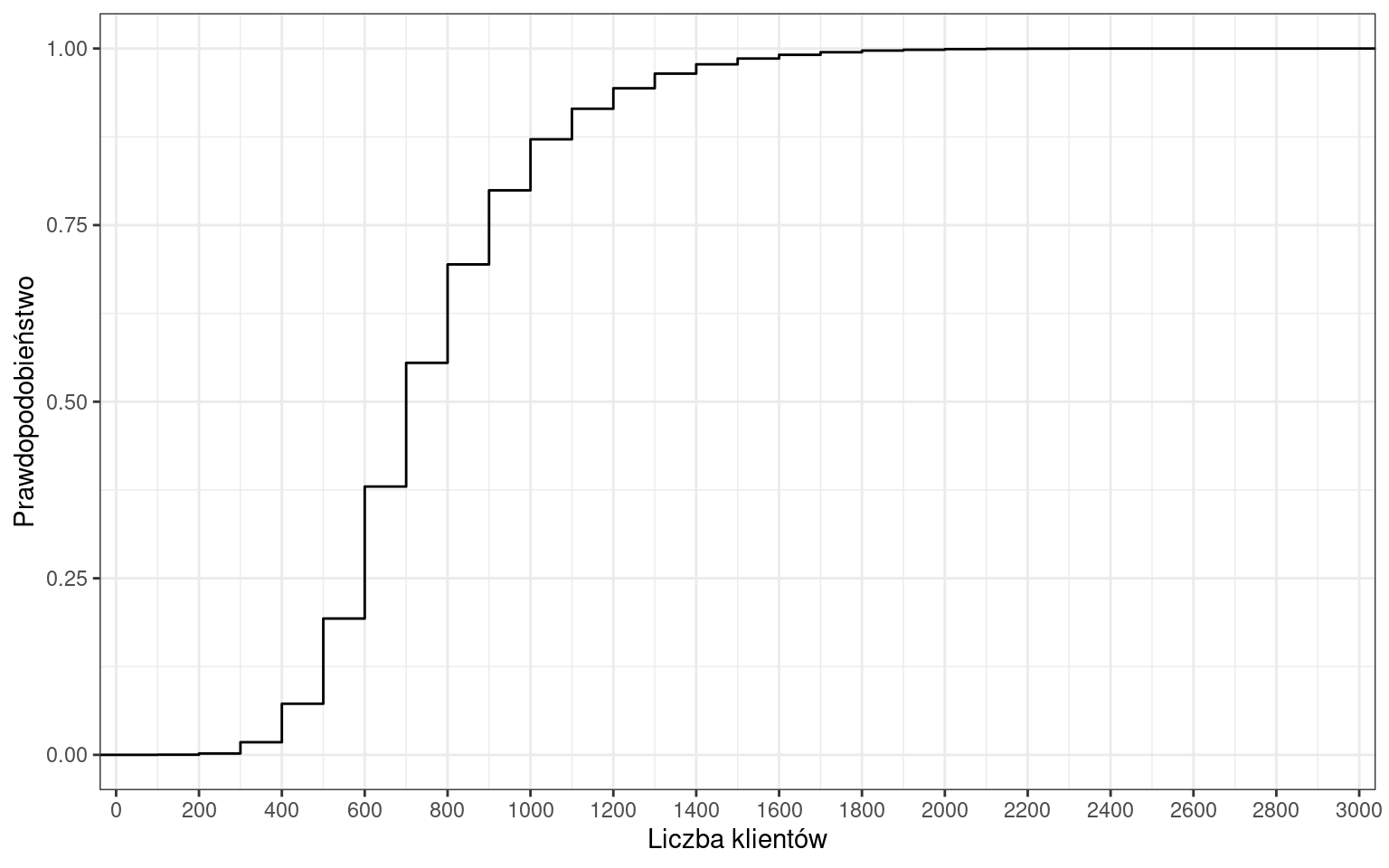
Przykładowo prawdopodobieństwo, że wystąpi dzień, w którym sklep obsłuży do 700 klientów wynosi 55%.
Zadania
Z wykorzystaniem histogramu lub innych poznanych podczas zajęć metod określ w jaki dzień tygodnia sklepy Rossmann odwiedza najwięcej klientów.